PCA란?
가장 인기 있는 차원 축소 알고리즘 중 하나로, 데이터에 가장 가까운 초평면을 해석적으로 정의한 후 그 평면에 데이터를 투영시키는 방법입니다.
# 분산 보존
PCA가 차원축소하는 방법으로 분산 보존이 있습니다. 우리는 저차원의 초평면에 훈련 세트를 투영하기 전에 올바른 초평면을 선택해야 합니다

- 위의 그림에서 보는 것과 같이, 다른 방향으로 투영하는 것 보다 분산이 최대로 보존하는 축을 선택하는 것이 정보가 가장 적게 손실됩니다. 즉, 분산이 최대로 보존하는 축은 원본 데이터 셋과 투영된 축 사이의 평균 제곱거리를 최소화하는 축입니다.
# 주성분이란?

i번째 축을 이 데이터의 i번째 주성분(PC, Principal Component)라고 하는데, i번째 축을 찾는 방법은 아래와 같습니다
- PCA는 훈련 세트에서 분산이 최대인 축을 찾습니다
- 첫번째 축에 직교하고 남은 분산을 최대로 보존하는 두번째 축를 찾습니다
- 고차원 데이터 셋이라면 PCA는 데이터셋에 있는 차원의 수 만큼 i번째 축을 찾습니다
- 위 그림에서 첫번째 PC는 벡터 C1이 놓인 축, 두번째 PC는 벡터 C2가 놓인 축
[ 주의할 점 ]
- 각 주성분을 파악하기 위해, PCA는 주성분 방향을 가리키고 원점에 중앙이 맞춰진 단위 벡터를 찾습니다
- 하나의 축에 단위 벡터가 반대 방향으로 두개 있기 때문에, PCA가 반환하는 단위 벡터의 방향(주성분의 방향)은 일정하지 않을 수 있습니다.
[ SVD (Single Value Decomposition, 특잇값 분해) ]
훈련데이터 셋의 주성분을 찾는 방법으로 특이값 분해가 있습니다. 특잇값 분해는 표준 행렬 분해 기술로, 훈련 세트 행렬 X를 세 개 행렬의 행렬 곱셈인 UΣVt로 분해할 수 있습니다. 찾고자하는 모든 주성분의 단위 벡터가 V에 다음과 같이 담겨 있습니다

svd()함수로 U, Σ, Vt를 얻을 수 있습니다
'''PCA는 데이터셋의 평균이 0이라고 가정합니다.
사이킷런의 PCA 파이썬 클래스는 이 작업을 대신 처리하기 때문에 따로 전처리를 하지 않아도 되지만,
PCA를 직접 구현하거나 다른 라이브러리를 사용한다면 먼저 데이터를 원점에 맞춰야 합니다'''
X_centered = X - X.mean(axis=0) # 원점에 중앙화 된 데이터
U, s, Vt = np.linalg.svd(X_centered)
# Vt는 다시 전치화하여, 0번째 열을 c1, 1번째 열을 c2로 추출할 수 있음
c1 = Vt.T[:, 0]
c2 = Vt.T[:, 1][ d차원으로 투영하는 방법 ]
d차원으로 투영하는 방법은 유사역행렬을 기반으로 진행합니다.
정의된 초평면은 분산을 가능한 최대로 보존하는 투영을 보장하기 때문에, 처음 d개의 주성분으로 정의한 초평면에 투영하여 데이터셋의 차원을 d차원으로 축소할 수 있습니다.
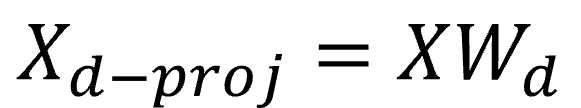
W2 = Vt.T[:, :2]
X2D = X_centered.dot(W2) #2차원으로 투영된 데이터셋- 초평면에 훈련 세트를 투영하고 d차원으로 축소된 데이터셋(Xd-proj)을 얻기 위해서는 행렬 X와 V의 첫 d열로 구성된 Wd를 곱합니다
# scikit-learn PCA모델
사이킷 런의 PCA모델은 SVD 분해 방법을 사용하여 구현합니다,
'''사이킷런의 PCA 파이썬 클래스는 원점 중앙화 작업을 대신 처리하기 때문에 따로 전처리를 하지 않아도 됩니다'''
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X2D = pca.fit_transform(X)
pca.explained_variance_ratio_
#array([0.84248607, 0.14631839])
#↑ 첫번째 PC : 84.2% , 두번째 PC : 14.6%- 주성분의 설명된 분산의 비율은 explained_variance_ratio_ 변수에 저장되어 있으며, 이 비율은 각 주성분의 축을 따라 나타나는 데이터 셋의 분산 비율을 나타냅니다
[ 적절한 차원 수 선택하는 방법 ]
적절한 차원 수를 선택하기 위해서는 축소할 차원 수를 임의로 정하기 보다는 충분한 분산(0.95)이 될때까지 더해야 할 차원 수를 선택하는 것이 간단합니다
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
mnist.target = mnist.target.astype(np.uint8)
X = mnist["data"]
y = mnist["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y)
pca = PCA()
pca.fit(X_train)
cumsum = np.cumsum(pca.explained_variance_ratio_)
d = np.argmax(cumsum >= 0.95) + 1
d
#154- 위의 예시코드는 고차원 데이터 MNIST 784차원 데이터를 예시로 PCA를 적용했을 때, 이 데이터의 설명된 분산의 비율( explained_variance_ratio_)의 누적합에서 0.95를 넘어서는 차원을 산정해본 코드입니다.
- 그 결과로, 154차원이 되었을 때, 95%를 넘어서는 것을 알수 있습니다
- 하지만, 데이터 시각화가 차원축소의 목적이라면 차원을 2~3개로 줄이는 것이 일반적입니다.
[ PCA에서 적절한 차원 수 선택하는 방법 ]
pca = PCA(n_components=0.95)
X_reduced = pca.fit_transform(X_train)- 유지하려는 주성분의 수를 지정하기 보다는, 분산의 비율을 n_componenets에 0.0~1.0사이로 설정하는 것이 효과적입니다
[ 압축 & 재복원 ]
PCA 기반으로 차원을 축소하고 난 후에는 훈련 세트의 데이터 크기가 줄어들며(압축), 추후 이를 다시 복원하는 기능(재복원)이 있습니다
- 분산의 95%를 유지하도록 PCA를 적용했을 떄, 대부분 분산은 유지되엇지만 데이터셋은 원본 크기의 20% 미만으로 변경되는데, 이러한 상당한 압축률은 분류알고리즘의 훈련 속도를 크게 높힐 수 있습니다
- 압축이후, inverse_transform 함수를 이용해 재복원기능을 사용할 수 있는데, PCA 투영의 변환을 반대로 적용하여 원래의 차원으로 되돌릴 수 있습니다
- 투영에서 잃어버린 일정량의 정보(유실된 5%의 분산)떄문에, 원본데이터셋과는 동일하게 되돌릴 수는 없습니다.
- 하지만, 원본데이터와 매우 비슷하며 원본데이터와 재구성된 데이터 사이의 평균제곱거리를 '재구성오차'라고 합니다
[ PCA 방법론① 랜덤 PCA ]
랜덤 PCA는 확률적 알고리즘을 사용해 처음 d개의 주성분에 대한 근삿값을 빠르게 찾는 방법입니다
rnd_pca = PCA(n_components=154, svd_solver="randomized", random_state=42)
X_reduced = rnd_pca.fit_transform(X_train)- svd_solver 매개변수를 'randomized'로 지정합니다
- svd_solver는 'auto'가 default값입니다
- m이나 n이 500보다 크고, d가 m이나 n의 80%보다 작으면 사이킷런은 자동으로 랜덤PCA 알고리즘을 사용하거나 완전한 SVD방식을 사용합니다
- 계산복잡도는 완전한 SVD방식 O(m*2^2)+O(n^3)이 아닌, O(m*d*2)+O(d^3)이기 때문에, d가 n보다 많이 작으면 완전 SVD보다 훨씬 빠릅니다
[ PCA 방법론② 점진적 PCA ]
점진적 PCA는 훈련세트를 미니배치로 나눈뒤 IPCA알고리즘에 한번에 라나씩 주입하여 실행됩니다.
from sklearn.decomposition import IncrementalPCA
n_batches = 100
inc_pca = IncrementalPCA(n_components=154)
for X_batch in np.array_split(X_train, n_batches):
print(".", end="")
inc_pca.partial_fit(X_batch)
X_reduced = inc_pca.transform(X_train)- SVD 알고리즘을 실행하기 위해 전체 훈련 세트를 메모리에 올려야한다는 PCA구현의 문제점을 해결할 수 있습니다
- 훈련세트가 클 때 유용하며, 새로운 데이터가 준비되는 대로 실시간 PCA 적용이 가능하여 온라인으로 PCA를 적용할 수 있습니다
m, n = X_train.shape
X_mm = np.memmap(filename, dtype="float32", mode="readonly", shape=(m, n))
batch_size = m // n_batches
inc_pca = IncrementalPCA(n_components=154, batch_size=batch_size)
inc_pca.fit(X_mm)- 넘파이의 Memmap을 활용하여 파일로 저장된 큰 배열을 메모리에 넣어 놓고 이용할 수 있습니다
# 비선형 PCA
[ 커널 PCA ]
커널 트릭 기법을 PCA에 적용해여 차원축소를 위한 복잡한 비선형 투영 수행을 가능하게 합니다. 투영된 후 샘플의 군집을 유지하거나 꼬인 매니폴드에 가까운 데이터 셋을 펼칠 때도 유용합니다
* 커널 트릭
커널 트릭은 샘플을 매우 높은 고차원 공간으로 암묵적으로 매핑하여, 서포트벡터머신의 비선형 분류와 회귀를 가능하게 하는 수학적 기법입니다
- 고차원 특성 공간에서 선형 결정 경계는 원본 공간에서 복잡한 비선형 결정 경계에 해당합니다
from sklearn.decomposition import KernelPCA
rbf_pca = KernelPCA(n_components=2, kernel="rbf", gamma=0.04)
X_reduced = rbf_pca.fit_transform(X)- 사이킷런에서는 KernelPCA를 제공합니다
- kernel 매개변수를 적절하게 적용하여 사용합니다. 아래는 각각 'linear', 'rbf', 'sigmoid' 커널을 사용하여 시각화한 사진입니다.

- 커널 PCA는 비지도 학습이므로, 좋은 커널과 좋은 하이퍼파라미터 선택을 위한 명확한 성능 측정 기준이 없습니다
- 하지만, 차원 축소는 종종 분류와 같은 지도학습의 전처리 단계로 활용되므로, 그리드 탐색을 사용하여 주어진 문제에서의 성능이 가장 좋은 커널과 하이퍼파라미터를 선택할 수 있습니다
- 또한, 재복원 후 원본과 재구성 오차를 최소화하는 커널과 하이퍼파라미터를 찾는 방법도 있습니다
https://github.com/sonzwon/TIL_DL/blob/master/Dimensionality_Reduction.ipynb
'AI > Machine Learning' 카테고리의 다른 글
| LLE (Locally Linear Embedding, 지역 선형 임베딩) (0) | 2022.12.12 |
|---|---|
| Dimensionality Reduction (차원 축소) (0) | 2022.12.09 |
| Decision Tree (결정 트리) (0) | 2022.12.06 |
| Support Vector Machine (SVM, 서포트백터머신) (0) | 2022.12.06 |
| Logistic Regression (로지스틱 회귀) (0) | 2022.12.06 |